Practical assessment with Moose
For humane assessment to be practical we need to craft the analysis tools effectively and efficiently.
Moose is a platform for software and data analysis that makes assessment practical by empowering the analyst to customize the flow of analysis, to craft new tools, and to iterate.
Moose in a nutshell
It is a free and open-source project started as a research project in 1996. Since then it spread to several research groups and it is increasingly being applied in industrial contexts. In total, the effort spent on Moose raises to several hundred person-years of research and development.
The design of Moose is rooted in the core idea of placing the analyst at the center and of empowering him to build and to control the analysis every step of the way. Data from various sources and in various formats is imported and stored in a model. For example, Moose can handle out of the box various languages via multiple meta-models: Java, JEE, Smalltalk, C++, C, XML.
![]()
On top of the created model, the analyst performs analyses, combines and compares the analyses to find answers to specific questions. Moose enables this in two distinct ways.
On the one hand, Moose comes with multiple predefined services such as: parsing, modeling, metrics computation, visualization, data mining, duplication detection, or querying. These basic services are aggregated into more complex analyses like computation of dependency cycles, detection of high level design problems, identification of exceptional entities and so on. An important characteristic is that the results of applying an analysis yields another set of entities that enriches the original model and that can be used as an input for further analyses. In this way, the desired analysis can be refined iteratively, and the whole process becomes a playful dialog between the analyst and the data.
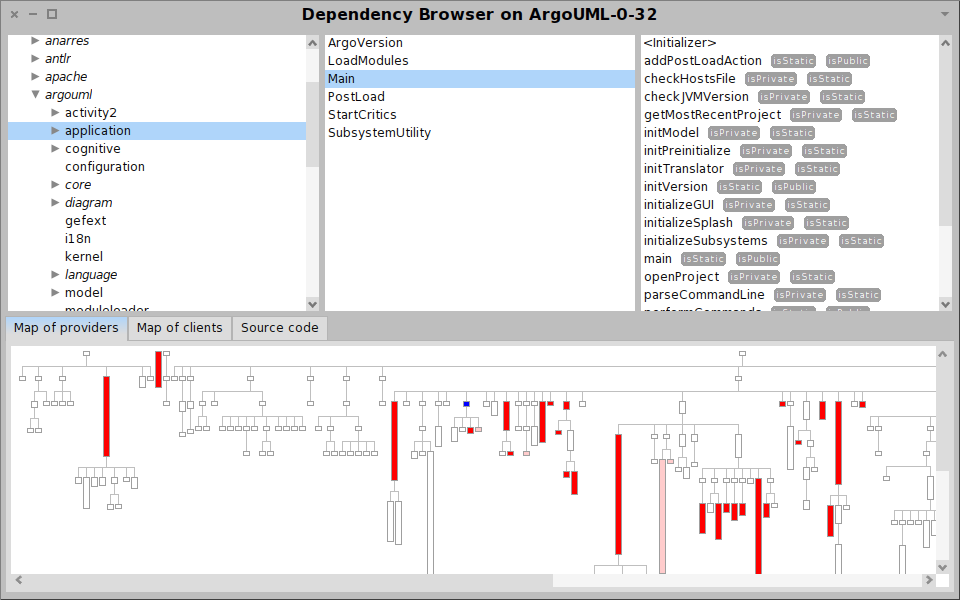
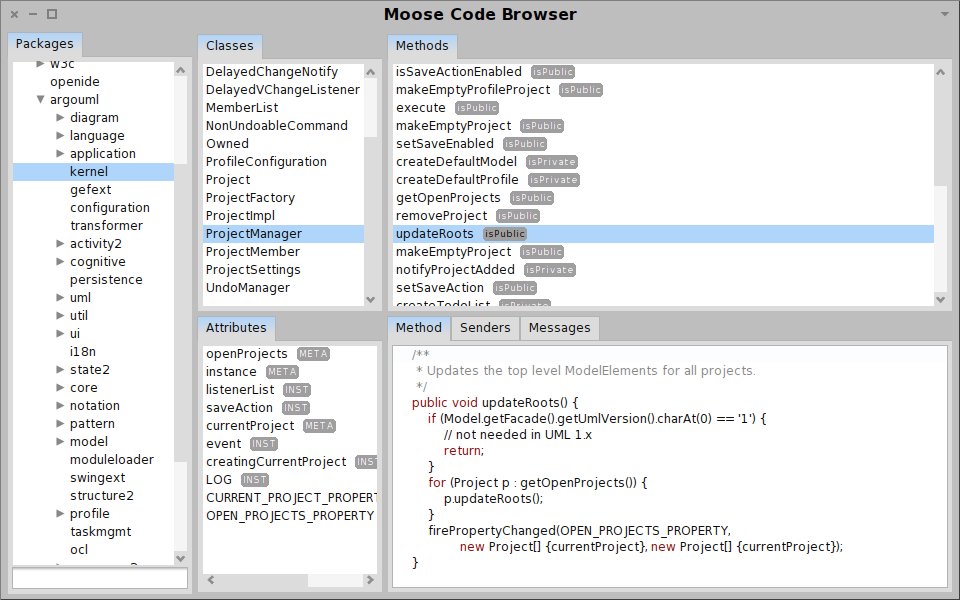
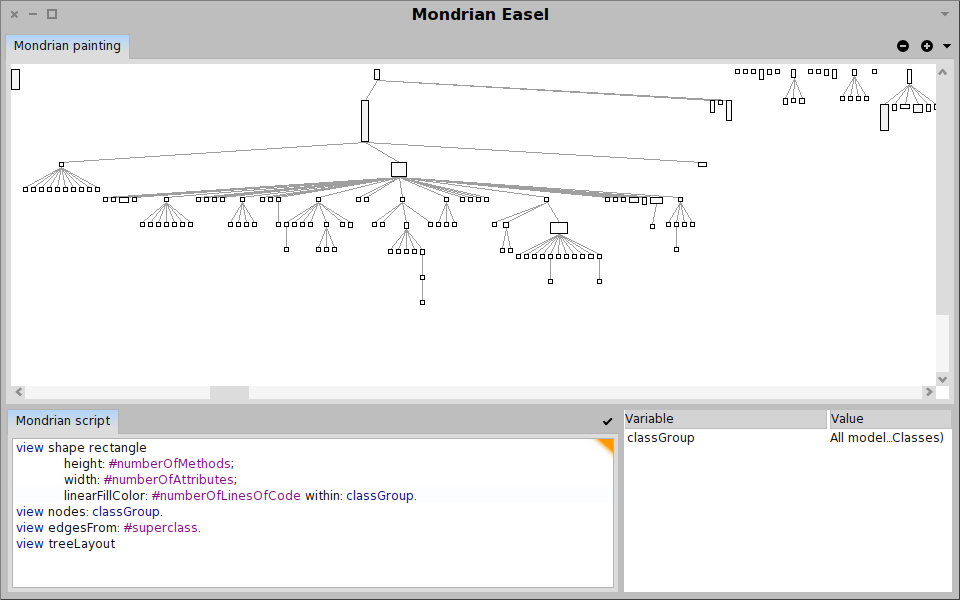
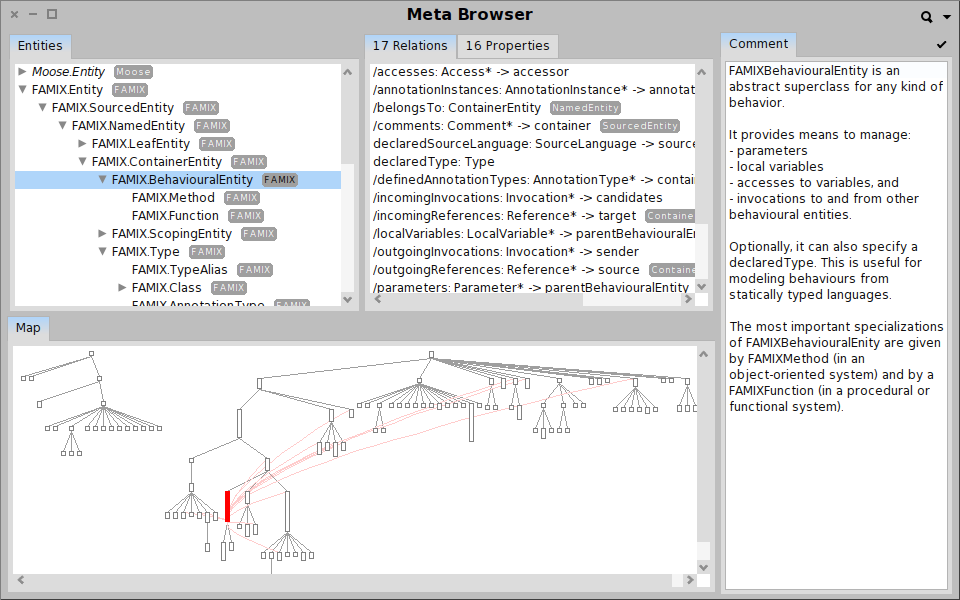
On the other hand, Moose is more than a tool. Moose is a platform that offers an infrastructure through which new analyses can be quickly built and can be embodied in new interactive tools. Using Moose we can easily define new analyses, create new visualizations, or build complete browsers and reporting tools altogether.
Moose in pictures
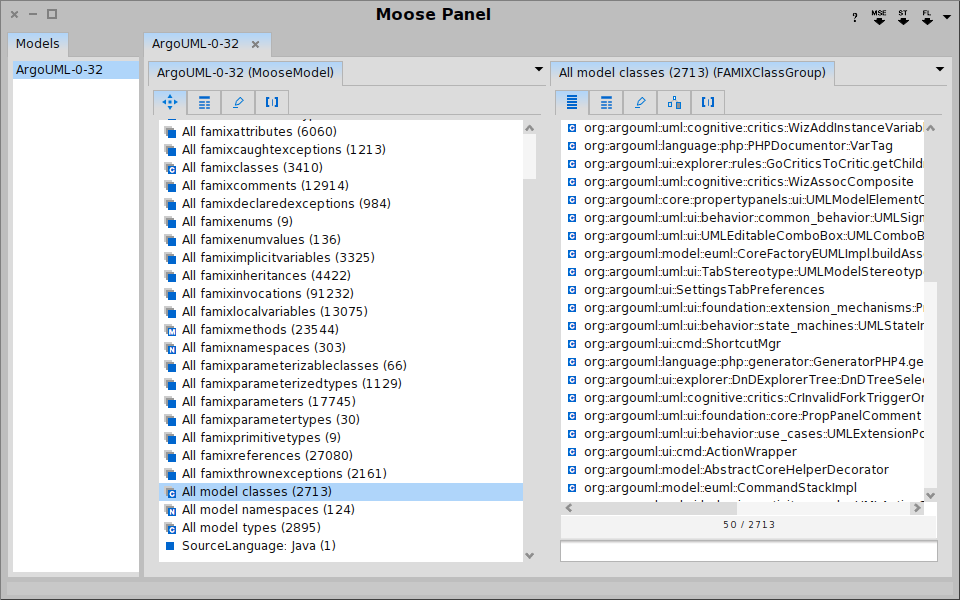
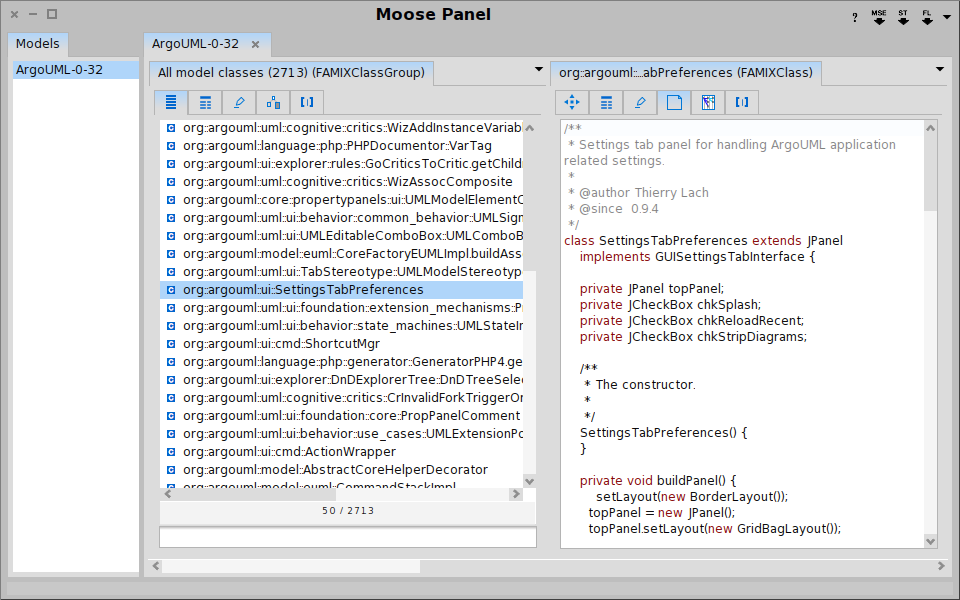
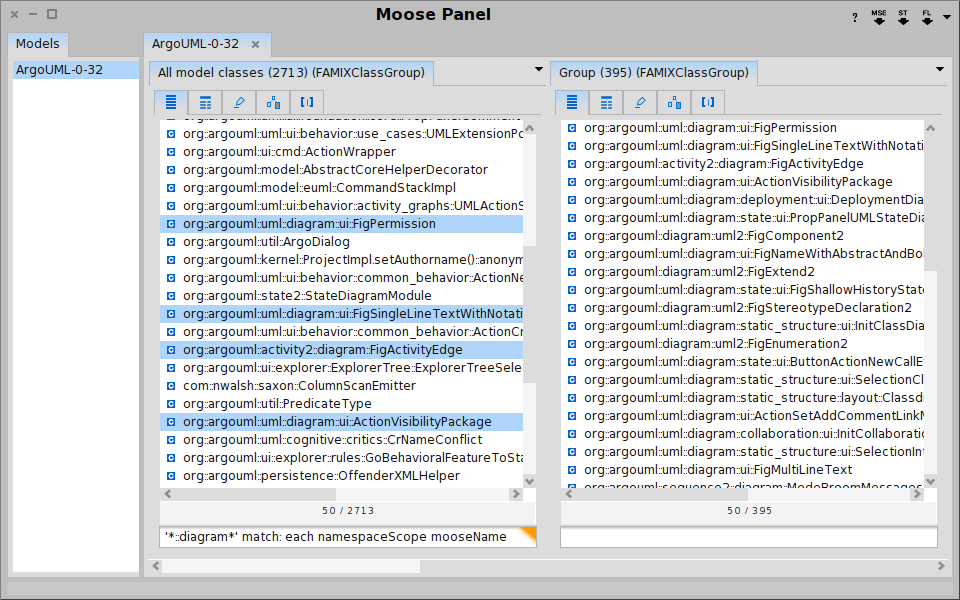
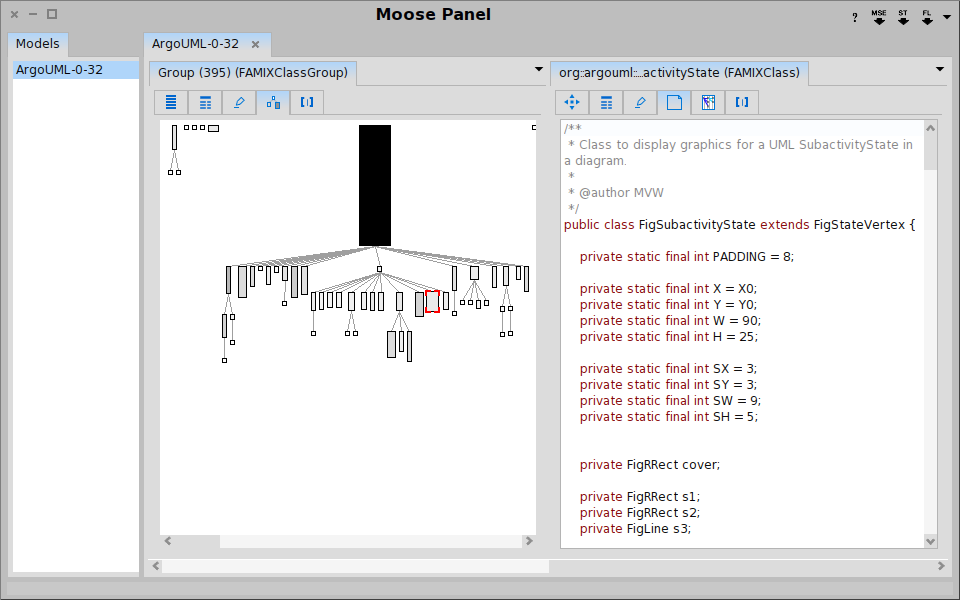
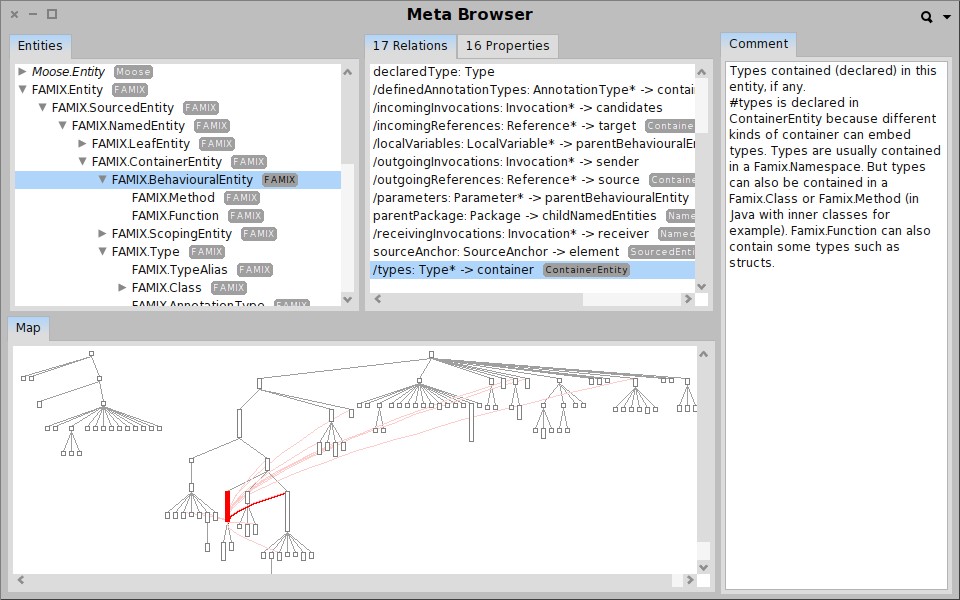
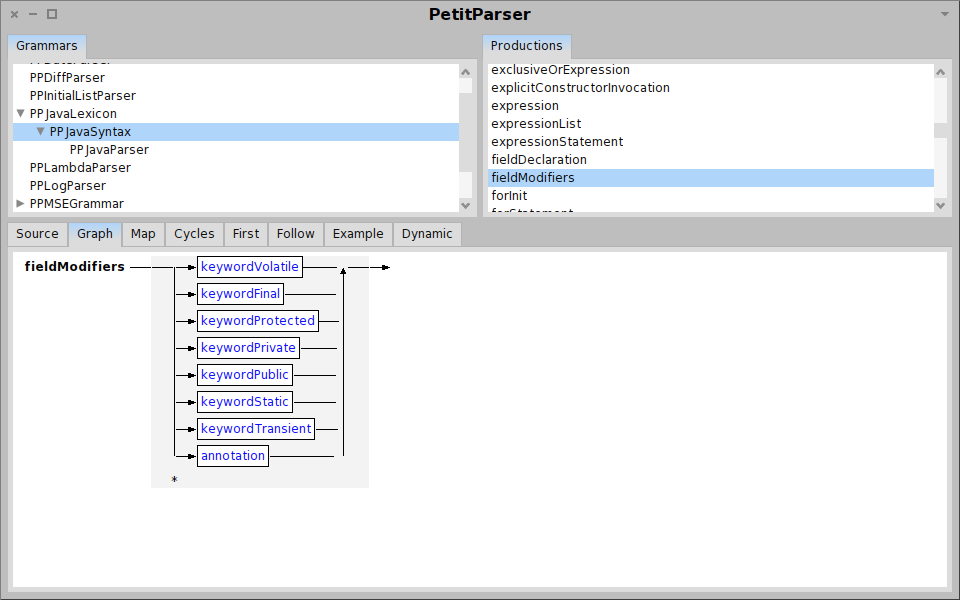
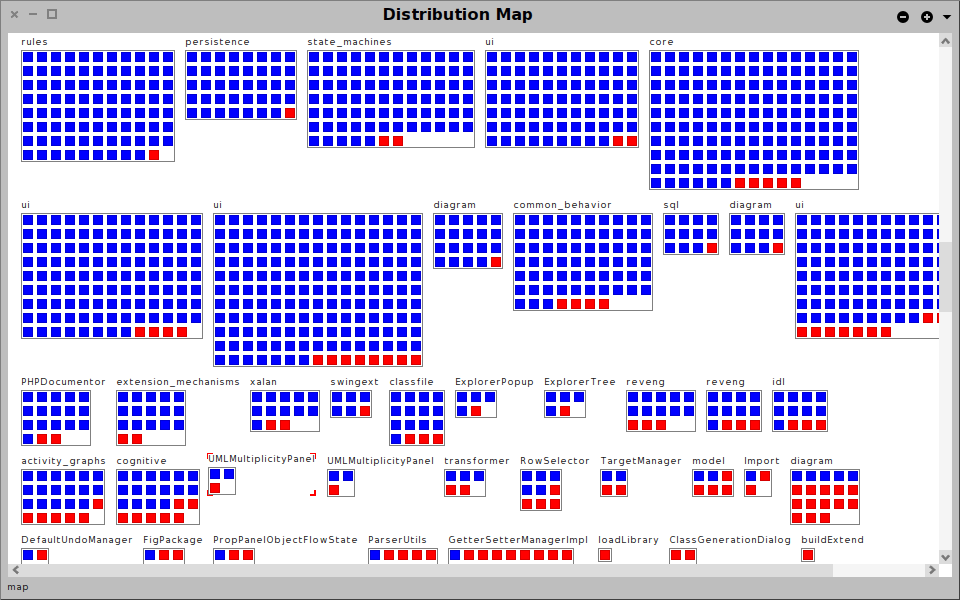
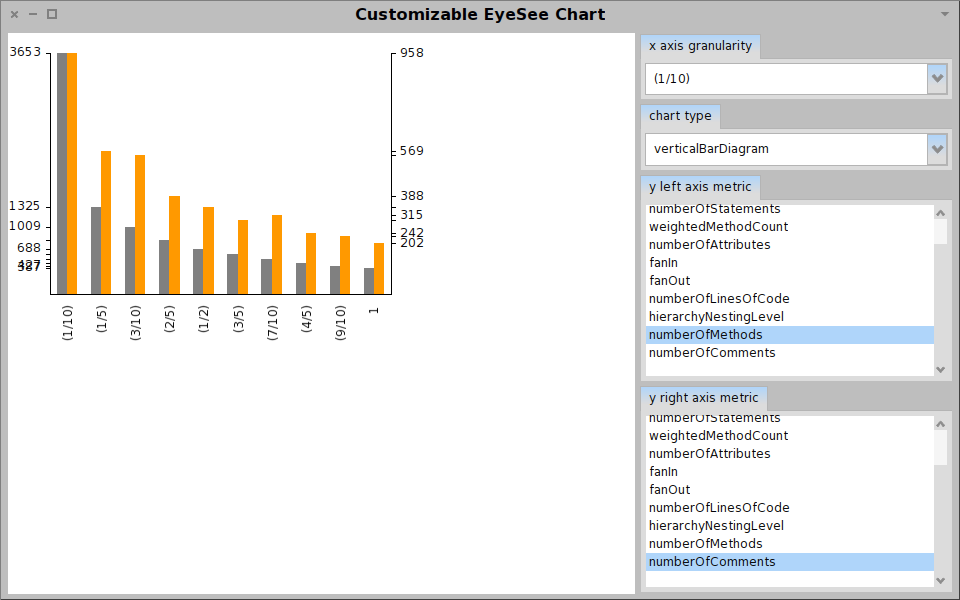
Summary
All in all, Moose offers a fresh perspective on how assessing software systems, or data in general, can and should be.
The current software development culture tends to promote tools as being something to conform to. Moose turns this state of facts upside down by empowering the development team to take complete control over the needed tools. And then it makes the process practical by bringing the cost of building a tool as close to zero as possible.
More information
More information about Moose can be found on the official website, or by reading The Moose Book.
